Renat není poprvé hostem autora na Lifehackeru. Dříve jsme od něj publikovali vynikající materiály o tom, jak vytvořit plán výcviku: základní knihy a online zdroje, stejně jako postupný algoritmus pro vytvoření tréninku.
Tento článek obsahuje jednoduché techniky, které usnadňují práci v aplikaci Excel. Jsou vhodné zejména pro ty zapojený do manažerského výkaznictví, připravuje řadu analytických zpráv založených na sázení 1C a dalších zpráv, formy z nich prezentace a tabulky řízení. Nepokládám za absolutní novinku – v jisté podobě tyto techniky jistě byly diskutovány na fórech nebo zmíněny v článcích.
Jednoduché alternativy VLOOK a GPR, pokud požadované hodnoty nejsou v prvním sloupci tabulky: VIEW, INDEX + MATCH
Funkce VLOOKUP a HLOOKUP fungují pouze v případě, že jsou vyhledávací hodnoty v prvním sloupci nebo řádku tabulky, od které chcete data přijmout.
V ostatních případech existují dvě možnosti:
- Použijte funkci LOOKUP.
Má následující syntaxi: VIEW (required_value; vector_view; vektor výsledku). Pro správné fungování je však nutné, aby hodnoty rozsahu vector_view byly seřazeny podle vzestupného pořadí: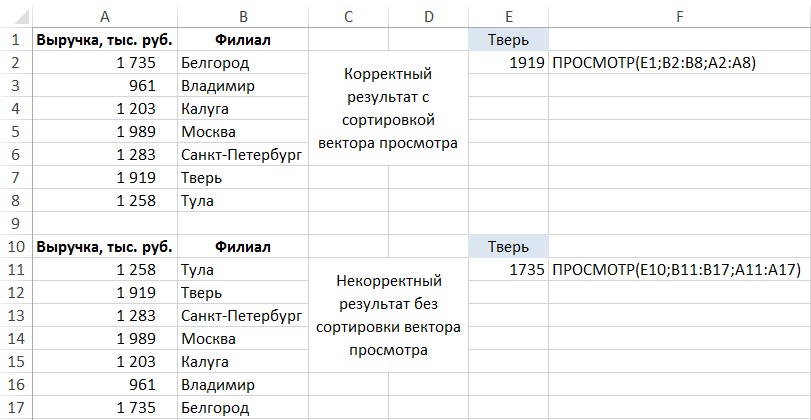
- Použijte kombinaci funkcí MATCH a INDEX.
Funkce MATCH vrátí pořadové číslo prvku v poli (s jeho pomocí můžete najít požadovanou položku v tabulce v řadě), a funkce INDEX vrací prvek pole s předem určený počet (což se učíme prostřednictvím shoda).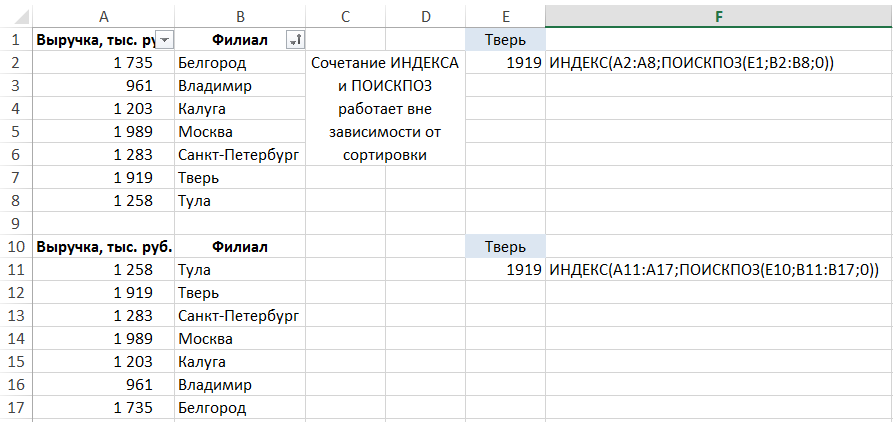 Syntaxe funkcí:
Syntaxe funkcí:
• MATCHOVÁNÍ (required_value; vyhledávací pole; match_type) – pro náš případ potřebujeme typ shody “přesné shody”, odpovídá číslu 0.
• INDEX (pole; číslo řádku; [column_number]). V tomto případě by číslo sloupce nemělo být specifikováno, protože pole obsahuje jeden řádek.
Jak rychle vyplnit prázdné buňky v seznamu
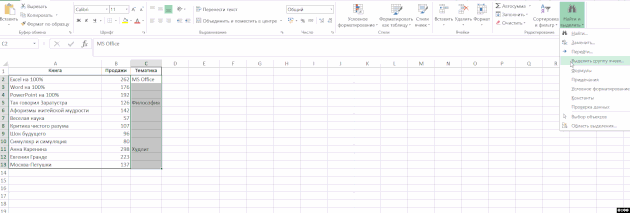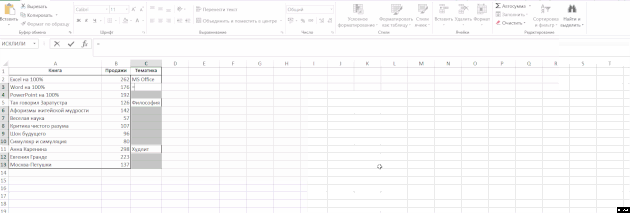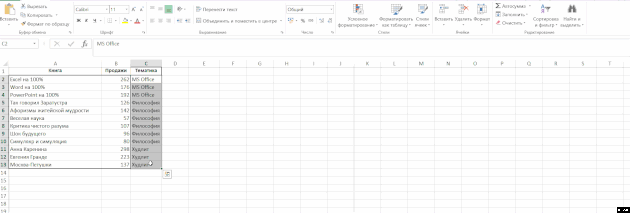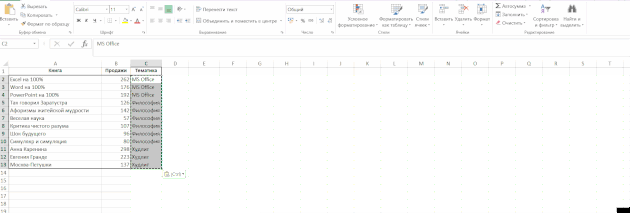
Úkolem je vyplnit buňky ve sloupci s hodnotami z horní části (takže téma je v každém řádku tabulky, a to nejen v prvním řádku bloku knih o předmětu):
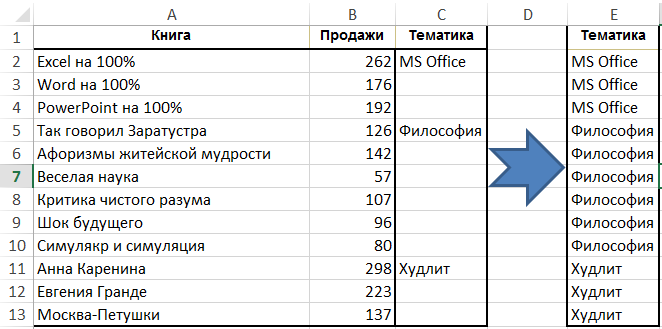
Vyberte sloupce „subjekt“, klikněte na pásce „Home“ skupiny, klikněte na tlačítko „Najít a zvolte» → «Označte skupinu buněk» → «Prázdné buňky“ a začněte zadávat vzorec (tj dát rovnítko) a odkazuje na buňku shora pouhým stisknutím tlačítka šipka nahoru na klávesnici. Poté stiskněte klávesy Ctrl + Enter. Poté můžete data uložit jako hodnoty, protože vzorce již nejsou potřeba:
Jak najít ve vzorci chyby
Výpočet samostatné části vzorce
Abychom porozuměli komplexní vzorec (která funguje jako argumenty používané jinou funkci, to znamená, že některé funkce jsou vložené do druhé), nebo najít v něm zdroj chyb, často potřebují k výpočtu její část. Existují dva jednoduché způsoby:
- Chcete-li vypočítat část vzorce přímo ve vzorci, vyberte tuto část a stiskněte klávesu F9:
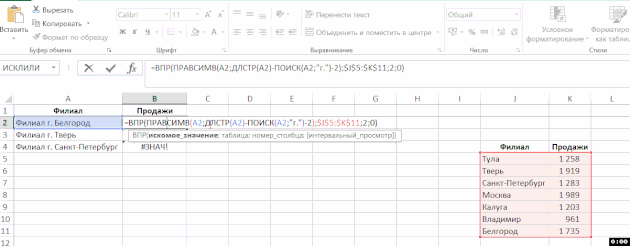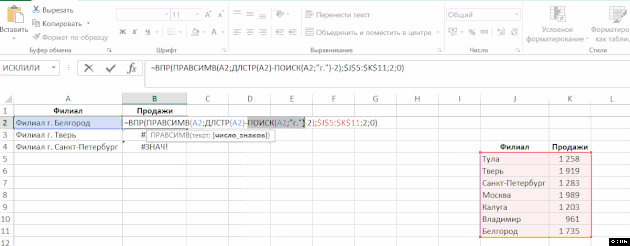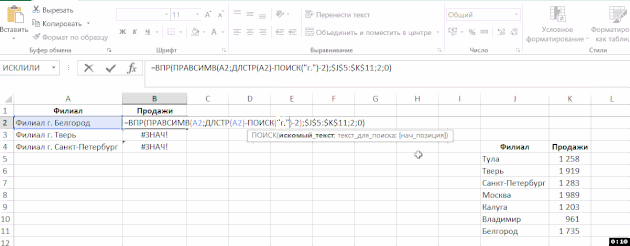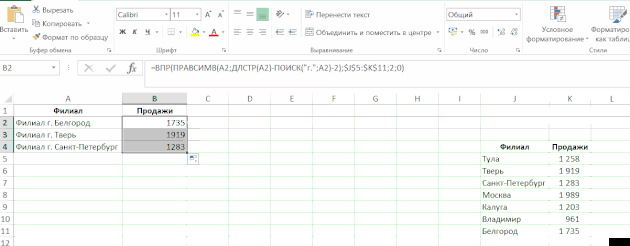
V tomto příkladu došlo k problému s funkcí SEARCH – byla zaměněna s argumenty. Je důležité si uvědomit, že pokud nezrušíte výpočet části funkce a stisknete Enter, vypočtená část zůstane číslem. - Klepněte na tlačítko “Vypočítat vzorec” ve skupině “Formule” na pásu:
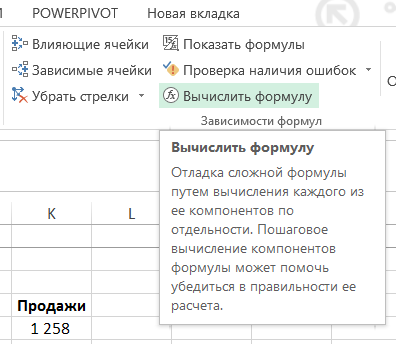
V okně, které se zobrazí, můžete vypočítat vzorec podle kroků a zjistit, v jaké fázi a v jaké funkci nastane chyba (pokud existuje):
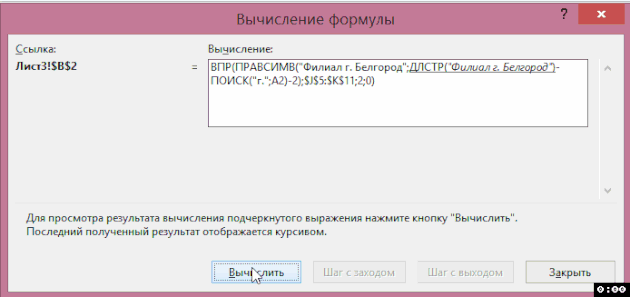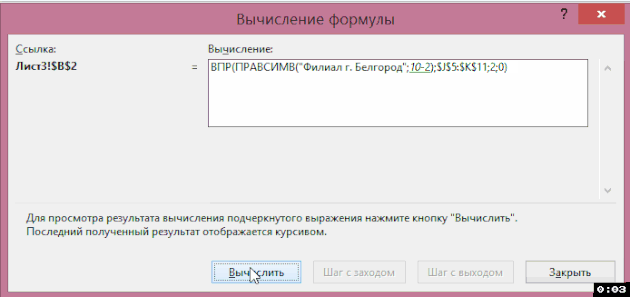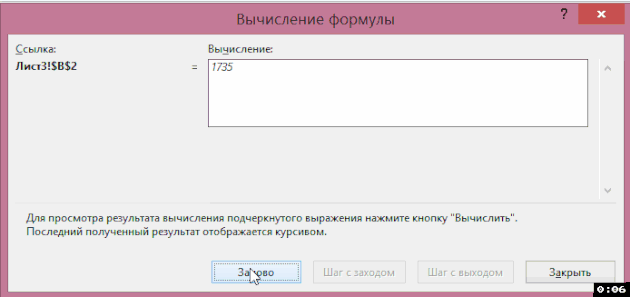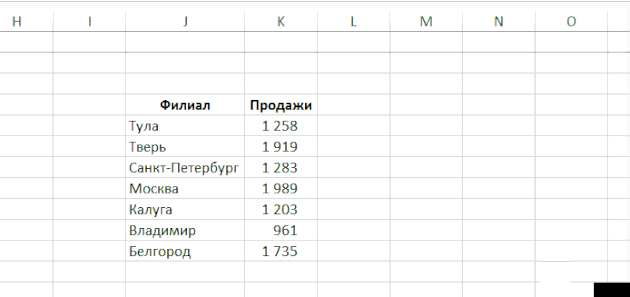
Jak zjistit, na čem závisí vzorec nebo na který se vztahuje
Chcete-li zjistit, od kterého buňky závisí vzorec, v skupině “Formuláře” na pásu karet klepněte na tlačítko “Influence cells”
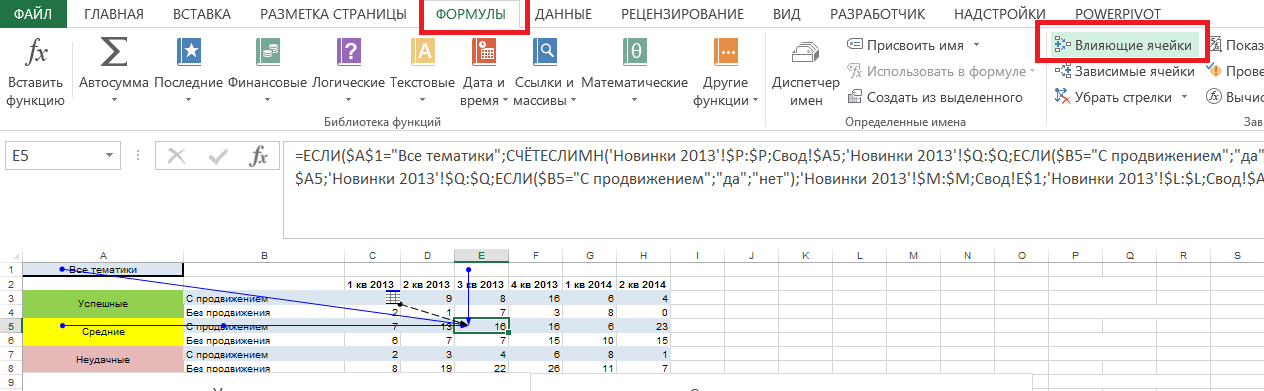
Zobrazí se šipky, na kterých závisí výsledek výpočtu.
Pokud je symbol zvýrazněný na obrázku zobrazen červeně, vzorec závisí na buňkách na jiných listech nebo v jiných knihách:

Kliknutím na něj uvidíme přesně, kde se nacházejí ovlivňující buňky nebo rozsahy:
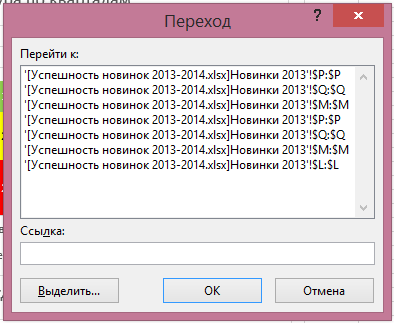
Vedle tlačítka “Ovlivňující buňky” je tlačítko “Závislé buňky”, které funguje podobně: zobrazuje šipky z aktivní buňky pomocí vzorce na buňky, které na něm závisí.
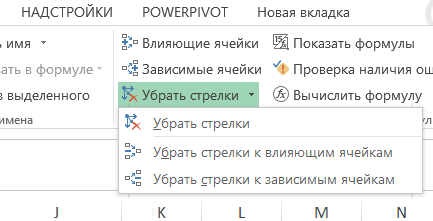
Tlačítko “Odebrat šipky” umístěné ve stejném bloku umožňuje odstranit šipky na ovlivňující buňky, šipky na závislé buňky nebo na obě typy šípů najednou:
Jak najít množství (počet, průměr) hodnot buňky z několika listů
Řekněme, že máte několik listů stejného typu s daty, které chcete přidat, počítat nebo zpracovávat něco jiného:
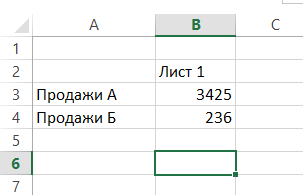
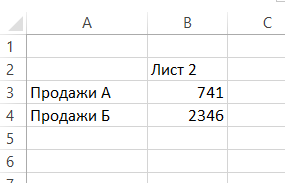
K tomu je buňka, ve které chcete vidět výsledek, zadejte standardní vzorec, jako například SUM (součet) a zadejte argument následované dvojtečkou a příjmením prvního listu ze seznamu těch listů, je třeba zvládnout:
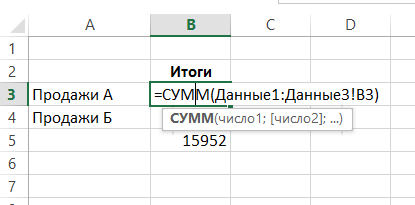
Získáte součet buněk s adresou B3 z listů “Data1”, “Data2”, “Data3”:
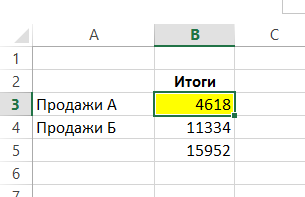
Toto adresování funguje pro umístění listů důsledně. Syntaxe je: = FUNKCE (první_list: last_list! odkaz na rozsah).
Jak automaticky vytvořit šablony frází
Pomocí základních principů práce s textem v aplikaci Excel a několika jednoduchých funkcí můžete připravit šablony pro zprávy. Několik principů práce s textem:
- Kombinujte text se znaménkem (můžete ji nahradit funkcí CONCATENATE, ale to nemá velký smysl).
- Text je vždy napsán v uvozovkách, odkazy na buňky s textem jsou vždy bez.
- Chcete-li získat symbol služby “uvozovek”, použijte funkci CHAR s argumentem 32.
Příklad vytváření šablony pomocí vzorců:

Výsledek:

V tomto případě, kromě funkční symbol (znak) (zobrazit uvozovek) pomocí funkce IF (IF), umožňuje změnit text, v závislosti na tom, zda pozitivní dynamiku prodejů tam, a funkci text (text), umožňující zobrazení čísla v libovolném formátu. Jeho syntaxe je popsána níže:
TEXT (hodnota; formát).
Formát je citován stejným způsobem jako v případě, že jste zadali vlastní formát v okně Formát buňky.
Automatizovat můžete také složitější texty. Ve své praxi jsem se automatizovat dlouhá, ale rutinní poznámky k účtům ve formátu „padla / zvýšil o XX o plánu především v důsledku zvýšení / snížení FAKTORA1 XX, zvýšení / snížení FAKTORA2 YY …» se seznamem měnící faktorů. Pokud píšete takové připomínky často a proces psaní může algoritmizace – stojí jednou zmatený vytvořit vzorec nebo makro, které vám ušetří alespoň z části práce.
Jak uložit data v každé buňce po sloučení
Když kombinujete buňky, uloží se pouze jedna hodnota. Program Excel varuje při pokusu o sloučení buněk:
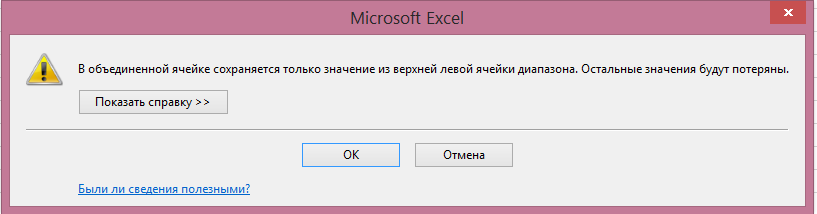
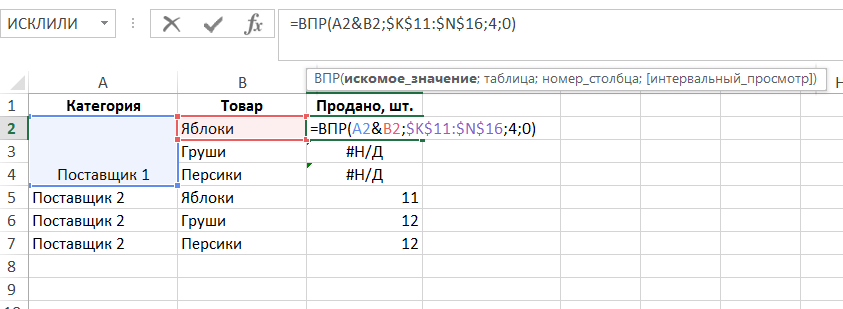
Proto pokud jste měli vzorec, který závisí na každé buňce, přestane fungovat po jejich skládání (# N / A chyba v řádcích 3-4 příkladu):
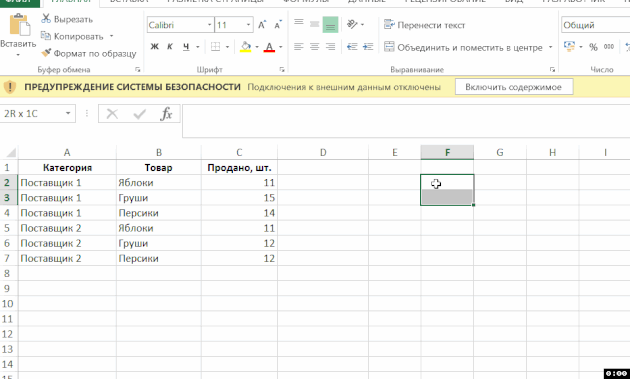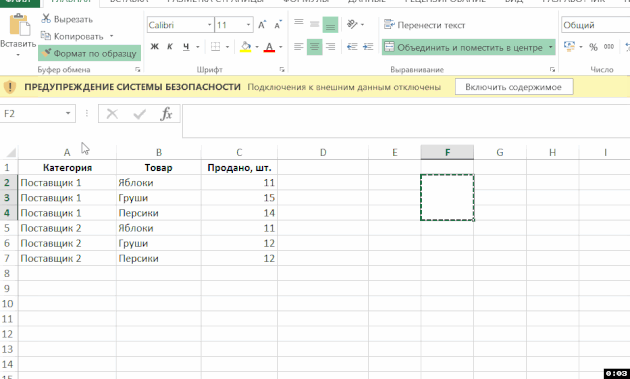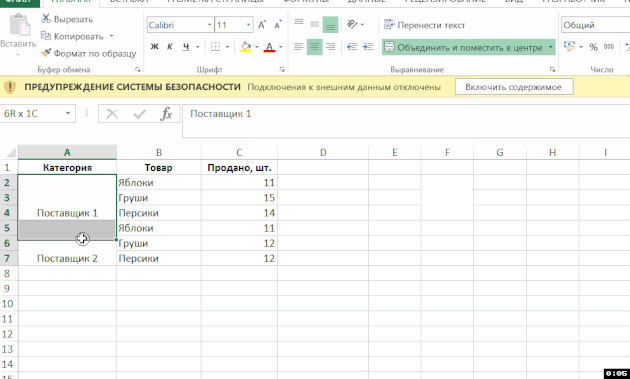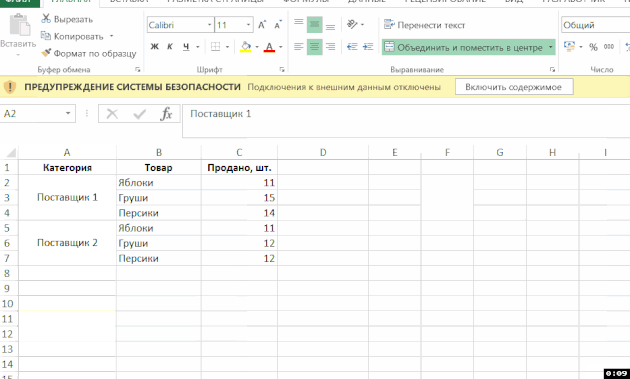
Chcete-li sloučit buňky, při zachování dat v každé z nich (možná máte vzorec, jak je v této abstraktní Například můžete chtít, aby sloučení buněk, ale zachovat všechna data v budoucnosti, nebo se skrýt své záměry), kombinují všechny buňky v listu , vyberte je a poté použijte příkaz “Formát podle vzoru”, přesuňte formátování na buňky, které chcete spojit:
Jak vytvořit složku několika zdrojů dat
Pokud potřebujete vytvořit konsolidovaný z více zdrojů dat, je nutné přidat k pásku nebo v panelu nástrojů „kontingenční Wizard a grafy“ Rychlý přístup, ve kterém existuje taková možnost.
Můžete to provést následujícím způsobem: “Soubor” → “Možnosti” → “Panel nástrojů Rychlý přístup” → “Všechny příkazy” → “Průvodce kontingentem a grafem” → “Přidat”
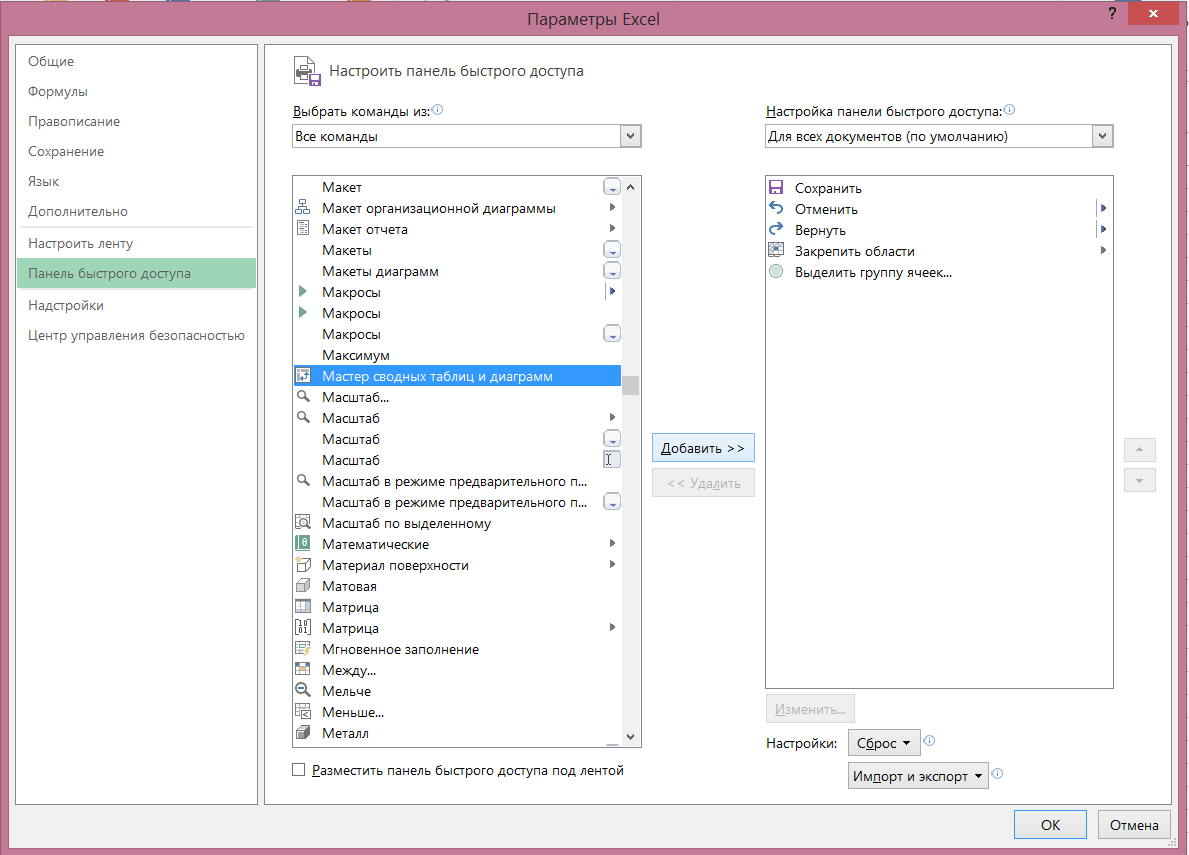
Poté se na pásku objeví příslušná ikona, klepnutí na které způsobí stejný průvodce:

Po klepnutí na něj se objeví dialogové okno:
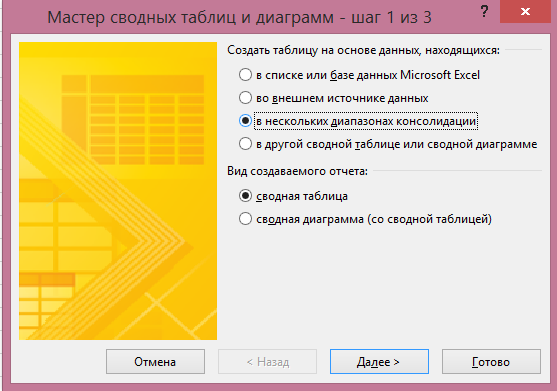
V tom je třeba vybrat “V několika konsolidačních rozsazech” a klikněte na “Další”. V dalším odstavci můžete zvolit možnost “Vytvořit jeden okraj stránky” nebo “Vytvořit okraje stránky”. Chcete-li vymyslet název každého zdroje dat sami, vyberte druhou položku:
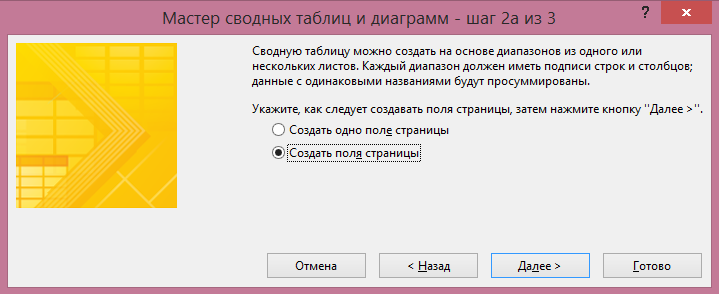
V dalším okně přidejte všechny rozsahy, na kterých bude shrnutí založeno, a dejte jim jména:
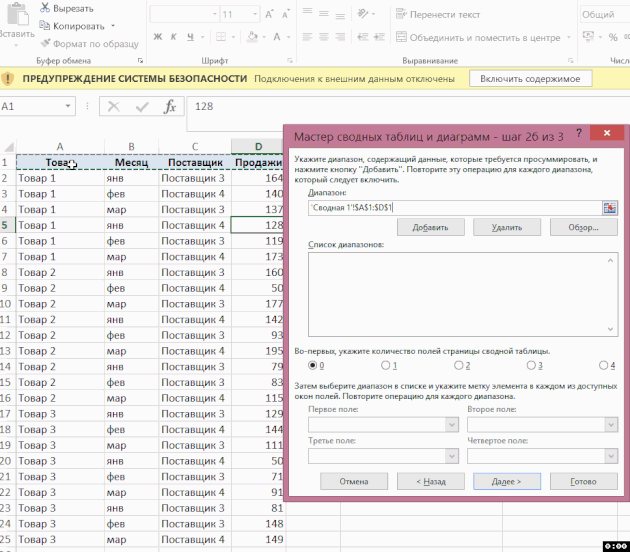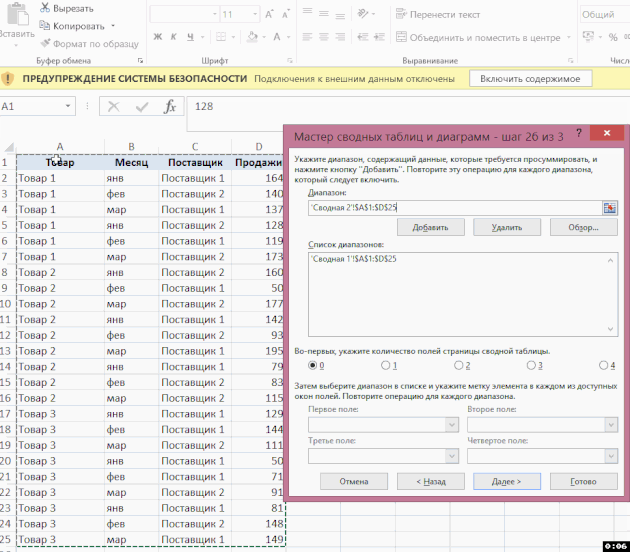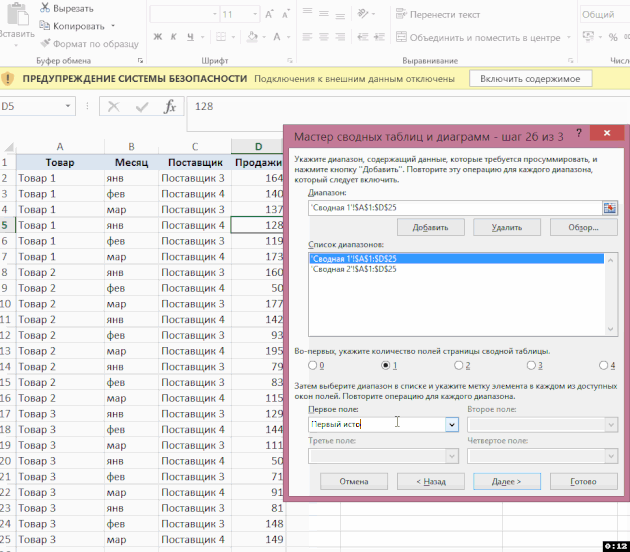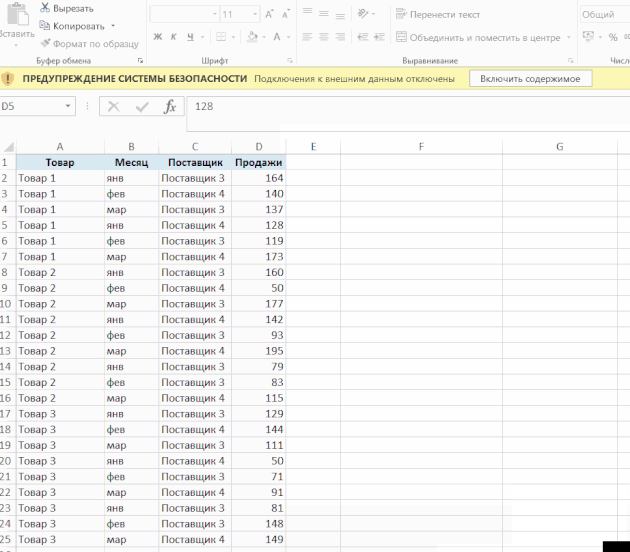
Poté v posledním dialogovém okně zadejte, kde bude umístěn přehled souhrnné tabulky – na existující nebo nový list:
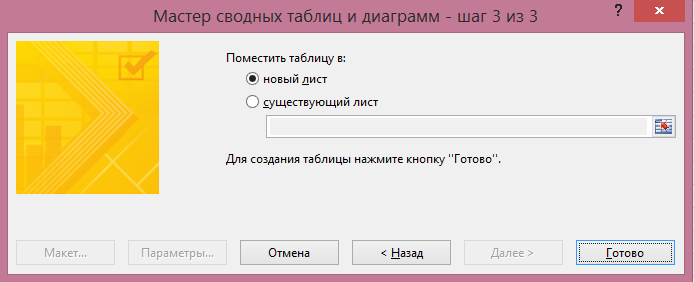
Přehled sestav tabulky je připraven. Ve filtru “Stránka 1” můžete v případě potřeby vybrat pouze jeden ze zdrojů dat:
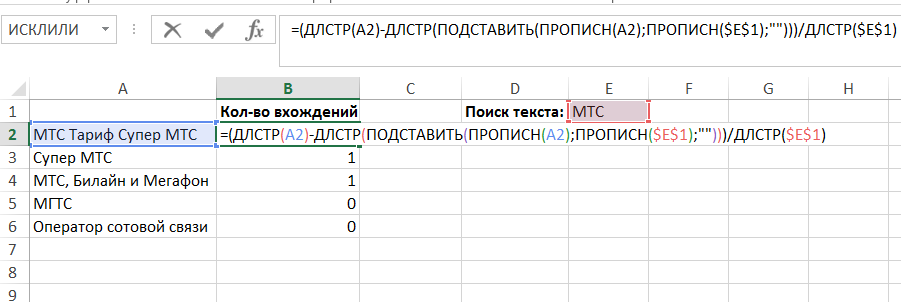
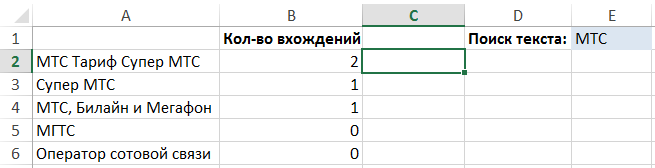
Jak vypočítat počet výskytů textu A v textu B (“MTS tarif SuperMTS” – dva výskyty zkratky MTS)
V tomto příkladu je ve sloupci A několik textových řetězců a naším úkolem je zjistit, kolikrát v každém z nich je hledaný text umístěný v buňce E1:
Chcete-li tento problém vyřešit, můžete použít složitý vzorec sestávající z následujících funkcí:
- LEN (LEN) – vypočte délku textu, jediný argument je text. Příklad: DLSTR (“stroj”) = 6.
- SUBSTITUTE – nahrazuje text v textovém řetězci jiným textem. Syntaxe: SUBSTRATE (text; old_text; new_text). Příklad: SUBMIT (“auto”; “auto”; “”) = “mobilní”.
- UPPER – nahrazuje všechny znaky řetězce velkými písmeny. Jediným argumentem je text. Příklad: PROPOSE (“stroj”) = “STROJ”. Tuto funkci potřebujeme k vyhledávání bez ohledu na velikost písmen. Koneckonců, PROPOSE (“stroj”) = PROPISN (“Stroj”)
Chcete-li zjistit výskyt určitého textového řetězce v jiném, musíte odstranit všechny jeho výskyty ve zdrojovém řetězci a porovnat délku přijatého řetězce s původním:
DLSTR (“Tarif MTS Super MTS”) – DLSTR (“Super tarif”) = 6
A rozdělíme tento rozdíl o délku řádku, který jsme hledali:
6 / DLSTR (“MTS”) = 2
Dvakrát řádek “MTS” je součástí původního řádu.
To zbývá být napsány v jazyce algoritmu vzorců (označený jako „text“ je text, který se snažíme vstup a „žádoucí“ – počet výskytů, které nás zajímají):
= (DLSTR (textu) -DLSTR (PŘEDLOŽTE (PROMISING (textu); PROPOSE (chtěl); “)))) / ДЛСТР (chtěl).
V našem příkladu vzorec vypadá takto:
(A2) -DLST (PODPORA (PRESENT (A2); PRESCRIPTION ($ E $ 1); DLR ($ E $ 1)